- 移动端


上海优宁维生物科技股份有限公司代理商
19 年
手机商铺
- NaN
- 0
- 0
- 2
- 2


斯达特
抗体/ELISA 试剂盒/试剂
已认证品牌介绍

Absin
生物化学/抗体
已认证品牌介绍

LabEx
技术服务
已认证品牌介绍

Cytiva
实验室仪器 / 设备/试剂/耗材/细胞库 / 细胞培养
已认证品牌介绍

Novus
抗体/试剂
已认证品牌介绍

Sigma-Aldrich
实验室仪器 / 设备/试剂/耗材
已认证品牌介绍

Thermo Fisher
试剂/实验室仪器 / 设备/耗材
已认证品牌介绍

Horizon Discovery
细胞库 / 细胞培养/技术服务/动物模型
已认证品牌介绍

Enzo
实验室仪器 / 设备/试剂
已认证品牌介绍

BiosPacific
抗体
已认证品牌介绍

Cayman
抗体/试剂
已认证品牌介绍

Bio X Cell
抗体/试剂
已认证品牌介绍

R&D Systems
试剂
已认证品牌介绍

Tocris bioscience
试剂
已认证品牌介绍

Innova Biosciences
抗体
已认证品牌介绍

Cell Signaling Technology
抗体
已认证品牌介绍

Biovision
试剂
已认证品牌介绍

Fitzgerald
试剂
已认证品牌介绍

LifeSpan BioSciences
抗体/试剂
已认证品牌介绍

AnaSpec
试剂
已认证品牌介绍

Sengenics
试剂/技术服务
已认证品牌介绍

Cytoskeleton
蛋白质/抗原/多肽/试剂
已认证品牌介绍

Synaptic Systems
试剂
已认证品牌介绍

USBiological
抗体/试剂
已认证品牌介绍

Agrisera
抗体
已认证品牌介绍

Meridian
抗体/试剂
已认证品牌介绍

Miltenyi Biotec
实验室仪器 / 设备/试剂
已认证品牌介绍

Alomone Labs
试剂
已认证品牌介绍
斯达特
抗体/ELISA 试剂盒/试剂
已认证品牌介绍
Absin
生物化学/抗体
已认证品牌介绍
LabEx
技术服务
已认证品牌介绍
Cytiva
实验室仪器 / 设备/试剂/耗材/细胞库 / 细胞培养
已认证品牌介绍



公司新闻/正文
罗工秘籍28-KeyWords二三事
279 人阅读发布时间:2021-09-24 10:11
KeyWords二三事: 使用关键字来组织和批处理您的数据
一、 什么是Keywords?
可用来定义样本间的差异(可多个关键词),将多个样本重新分组的依据
二、 快速添加新的关键词途径:(可添加多个关键词)
1、 首先选中一个样本,shift+Ctrl+I,输入关键词(英文),Workspace界面则生成新的一栏(关键词为抬头)
2、 首先选中一个样本,右键,选中Add Keywords,输入关键词(英文),Workspace界面则生成新的一栏(关键词为抬头)
三、 使用Flowjo已有的关键词作为(可添加多个关键词)
1、 shift+Ctrl+K,在Column Values列表里选择合适的参数,Add Column,OK
2、 右击一列的抬头,选择Edit Columns, 在Column Values列表里选择合适的参数,Add Column,OK
四、 每一个样本编辑对应合适的关键词字符
例如:关键词为刺激条件,每个样本需要编辑具体刺激条件是什么(英文简写或者数字代替)
五、 数据导出(Table Edit![]() )
)
1、 导入计算公式,例如Median值
首先选中要分析的细胞群体,右键,选择Add,Statistic,跳出弹窗;先选择Median,再选择Population的参数(比如IFN),点击Add(如不需要其他统计数据,可关掉弹窗,反之继续添加),添加成功后,样本群体下方会出现对应的公式和计算结果

2、 选中添加后的公式,右键,copy analysis to group,批量应用到其他样本上
3、 打开Table Edit(![]() )
)
4、 设置Group(All samples或各自Group);设置Iterate by(sample/Keyword)
5、 若是选择Iterate by sample,将一个样本的对应添加的公式直接拖拽到Table Edit界面上,可填写Name(自定义),然后点击Create Table;弹出结果Table,点击File,选择save as形式,进行保存。
6、 若是选择Iterate by Keywords,需要选择Iterate by 和 Discriminator各自的关键词
7、 同样向Table Edit界面拖拽对应的公式,注意点:需要拖拽不同样本下相同的公式,样本根据Discriminator选择的关键词来决定
举例:Iterate by STIM,Discriminator为SAMPLEID
1)则先确认,当前需要导出数据的样本中SAMPLEID关键词栏下的每个样本的标记,比如下图SAMPLEID栏,所有的样本中只有LD1和LD4两种标记;(如果Iterate by SAMPLEID,Discriminator为STIM,则确认STIM栏)
2)所以我们需要拖拽SAMPLEID标记为LD1和LD4两个样本下对应相同的公式到Table Edit中;
3)可填写Name(自定义),然后点击Create Table;弹出结果Table,点击File,选择save as形式,进行保存
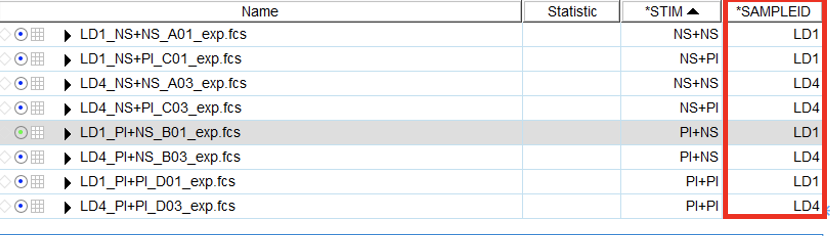
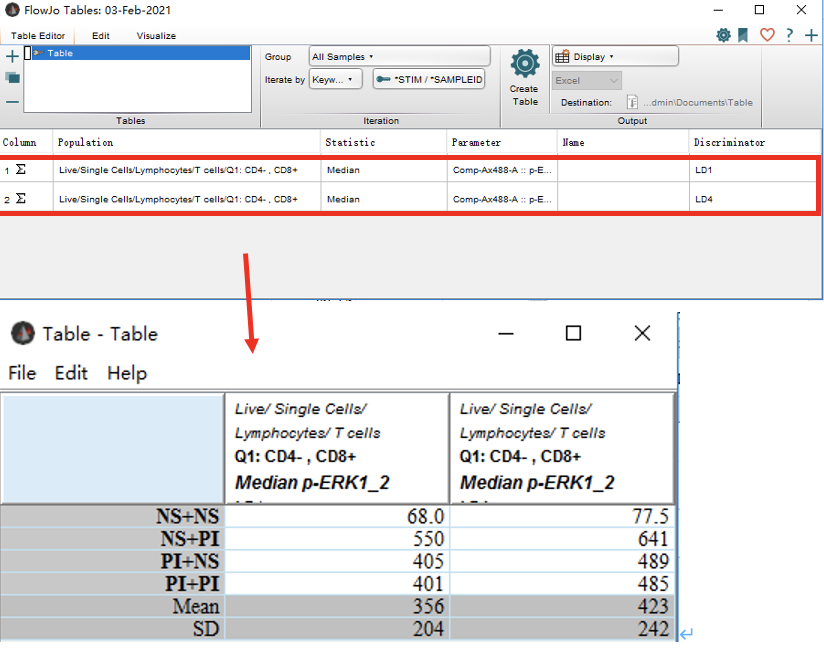
4)表格中数据从左往右和拖拽后的公式的排列顺序对应(如上图,第一列是LD1类型样本的数据,第二列是LD4类型样本的数据)
8、在Table界面,可点击Edit,点击select all,再右键,选择Heat Map,可制成热图